Why is this important?
Machine Learning has re-emerged in recent years as new Big Data platforms provide means to use them with more data, make them more complex as well as allowing combining several models to make an even more intelligent predictive/prescriptive analysis. This requires storing as well as exchaning machine learning models to enable collaboration between data scientists and applications in various environments. In the following paragraphs I will present the context of storing and deploying machine learning model, describe the dimensions into which model storage and deployment frameworks can be described, classify existing frameworks in this context and conclude with recommendations.
Context
Machine learning models usually describe mathematical equations with special parameters, e.g.
y = a*x +b with y as the output value, x as the input value and a/b are parameters.
The values of those parameters are usually calculated using an algorithm that takes training data as input. Based on the training data the parameters are calculated to fit the mathematical equation to the data. Then, one can provide an observation to the model and it predicts the output related to the observation. For instance, given a customer with certain attributes (age, gender etc.) it can predict if the customer will buy the product on the web page.
At the same time, as machine learning models grew more complex, they were used by multiple people or even developed jointly as part of large machine learning pipelines – a phenomena commonly known as data science.
This is a paradigm shift from earlier days where everyone mostly worked in isolation and usually one person had a good idea what an analysis was about.
While it is already a challenge to train and evaluate a machine learning model, there are also other difficult tasks to consider given this context:
- Loading/Storing/Composing different models in an appropriate format for efficient usage by different people and applications
- Reusing models created in one platform on another platform with a different technology and/or capacity considerations in terms of hardware resources
- Exchanging models between different computing environments within one enterprise, e.g. to promote models from development to production without the need to deploy potential risky code in production
- Discussing and evaluating different models by other people
- Offering pre-trained models in market places so enterprises can take/buy them and integrate then together with other prediction models in their learning pipeline
Ultimately, there is a need to share those models with different people and embed them in complex machine learning pipelines.
Achieving those tasks is critical to understand how machine learning models evolve and use the latest technologies to gain superior competitive advantages.
We describe the challenges in more details and then follow up how technologies, such as PMML or software container, can address them as well as how they are limited.
Why are formats for machine learning models difficult?
- Variety of different types of models, such as discriminative and generative, that can be stored. Examples are linear regression, logistic regression, support vector machines, neural networks, hidden Markov models, regenerative processes and many more
- An unambiguous definition of metadata related to models, such as type of model, parameters, parameter ontologies, structures, input/output ontologies, input data types, output data types, fitness/quality of the trained model and calculations/mathematical equations, needs to be taken into account
- Some models are very large with potentially millions/billions of features. This is not only a calculation problem for prediction, but also demands answers on how such models should be stored for most efficient access.
- Online machine learning, ie machine learning models that are retrained regularly, may need additional meta-data definitions, such as which data has been applied to them when, what data should be applied to them from the past, if any, and how frequently they should be updated
- Exchange of models between different programming languages and systems is needed to evolve them to newest technology
- Some special kind of learning models, e.g. those based on graph models, might have a less efficient matrix representation and a more efficient one based on lists. Although there are compression algorithms for sparse matrixes, they might not be as efficient for certain algorithms as lists
- Models should be easy to version
- Execution should be as efficient as possible
Generic Ways on Managing Machine Learning Models
We distinguish storage approaches for machine learning models across the following dimensions:
– Low ambiguity / high ambiguity
– Low flexibility / high flexibility
Ideally, a model has low ambiguity and high flexibility. It is very clear (low ambiguity) what the model articulates, so it can be easily shared, reused, understood and integrated (possibly automatically) in complex machine learning pipelines. High ambiguity corresponds to a black-box approach: some code is implemented, but nobody knows what it does, what are the underlying scientific/domain/mathematical/training assumptions/limitations. This makes those models basically useless, because you do not know their impact on your business processes.
Furthermore, one can articulate all possible models of any size until now as well as in the future, which correspond to high flexibility.
Obviously, one may think that low ambiguity and high flexibility is the ideal storage format. However, this introduces also complexity and a much higher effort to master it. In the end it always depends on the use case and the people as well as applications working with the model.
In the following diagram you see how different model storage formats could be categorized across different dimensions.
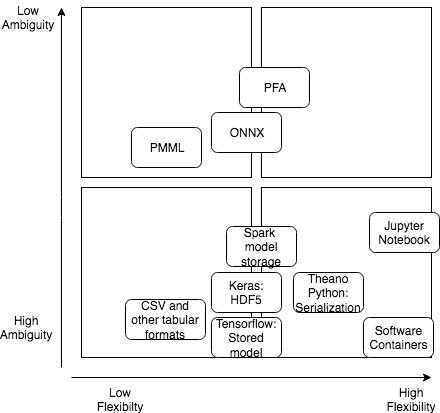
In the following we describe in more detail what these storage formats are and how I came up with the categorization:
CSV (Comma-Separated Values) and other tabular formats (e.g. ORC, Parquet, Avro):
Most analytical tools allow to store machine learning models in CSV or other tabular formats. Although many analytical tools can process CSV files, the CSV or other tabular formats do not adhere to a standard on how columns (parameters of the model) should be named, how data types (e.g. doubles) are represented and there is no standard on how metadata should be described. It does not describe anyway on how it can be loaded/processed or any computations to be performed. In virtually all cases the CSV format requires for each tool to implement a custom ETL process to use it as a model when loading/storing it. Hence, I decided it is low flexibility, because any form of computation is defined outside the CSV or other tabular format. One advantage with respect to flexibility is that with CSV and much more with specialized tabular formats (ORC, Parquet etc.) one can store usually very large models. In conclusion is categorized as High Ambiguity and Low flexibility.
PMML (Predictive Model Markup Language):
PMML exists already since 1997 and is supported by many commercial and open source tools (Apache Flink, Apache Spark, Knime, TIBCO Sportfire, SAS Enteprise Miner, SPSS Clementime, SAP Hana). PMML is based on XML (eXtensible Markup Language) and is articulated as an XML Schema. Hence, it reduces significantly ambiguity by providing a meta model around how transformations, models are described. Although this meta model is very rich, it does include only a subset of algorithms (many popular ones though) and it cannot be easily extended with new transformations or models that are then automatically understand by all tools. Furthermore, the meta model does not allow to articulate on which data the model was trained or on which ontology/concepts the input, output data is based. The possible transformations and articulated models do make it more flexible then pure tabular formats, but since it is based on XML it is not suitable for very large models containing a lot of features.
PFA (Portable Format for Analytics):
PFA is a more recent storage format compared to PMML and appeared around 2008. That means also that contrary to PMML it includes design considerations for “Big Data” volumes by taking into account Big Data platforms. Its main purpose is to exchange, store and deploy statistical models developed in one platform in another platform. For instance, one may write a trained model in Python and use it for predictions in a Java application running on Hadoop. Another example is that a developer trains the model in Python in the development environment and stores it in PFA to deploy it securely in production where it is run in a security-hardened Python instance. As you see it is already very close to the use cases described above. Additionally it takes into account Big Data aspects by storing model data itself in AVRO format. The nice thing is that you can actually develop your code in python/Java etc. and then let a library convert it to PFA, ie you do not need to know the complex and little bit cumbersome syntax of PFA). As such it provides a lot of means to reduce ambiguity by defining a standard and a large set of conformance checks towards the standard. This means if someone develops PFA support for a specific platform/library then it can be ensured that it adheres to the standard. However, ambiguity cannot be estimated as very low, because it has no standardized means to describe input and output data as part of ontologies or fitness/underly training assumptions. PFA supports definition of a wide range of existing models, but also new ones by defining actions and control flow/data flow operators as well as a memory model. However, it is not as flexible as e.g. developing a new algorithm that specially takes into account specific GPU features to run most-efficiently. Although you can define such an algorithm in PFA, the libraries used to interpret PFA will not know how to optimize this code for GPUs or distributed GPUs given the PFA model. Nevertheless, for the existing predefined models they can of course derive a version that runs well on GPUs. In total it has between low – medium ambiguity and high – medium flexibility.
ONNX (Open Neural Network Exchange Format):
ONNX is another format for specifying storage of machine learning models. However, its main focus are neural networks. Furthermore, it has an extension for “classical” machine learning models called ONNX-ML. It supports different frameworks (e.g Caffe2, Pytorch, Apple CoreML, TensorFlow) and runtimes (e.g. Nvidia, Vespa). It is mostly Python-focused, but some frameworks, such as Caffe2 offer a C++ binding. Storage of ML models is specified in protobuf, which offers itself already a wide tool support, but is of course not ML specific. It offers description of meta data related to a model, but in a very generic sense of key value pairs, which is not suitable to describe ontologies. It allows to specify various operators that are composed by graphs describing the data flow. Datatypes that are used as part of input and output specifications are based on protobuf datatypes. Contrary to PFA ONNX does not provide a memory model. However, similarly to PFA it does not allow the full flexibility, e.g. to write code in GPUs. In total it has between low – medium ambiguity and between high – medium flexibility, but ambiguity and flexibility are a little bit lower than PFA.
Keras stores a machine learning model in HDF5, which is a dedicated format for „managing extremely large and complex data collections“. HDF5 itself supports many language ranging from Python over C to Java. However, Keras is mostly a Python library. HF5 claims to be a portable file format and suitable for high performance as it includes special time and storage space optimizations. HDF5 itself is not very well supported by Big Data platforms. However, Keras stores in HDF5 architecture of the model, weights of the model, training configuration and the state of the optimizer to allow resume training were it was left off. This means contrary to simply using a tabular format as described before, it sets a standard for expressing models in a tabular format. It does not store itself training data or any more meta data beyond the previously described items. As such it has from medium to high ambiguity. Flexibility is between low and medium, because it can describe more easily models or state of the optimizer.
Tensorflow has its own format for loading and storing a model, which includes variables, the graph and graph metadata. Tensorflow claims the format is language-neutral and recoverable. However, it is mostly used in the Tensorflow library. It provides only few possibilities to express a model. As such it has high – medium ambiguity. Flexibility is higher than CSV and ranges from low to medium.
Apache Spark Internal format for storing models (pipelines)
Apache Spark offers storing a pipeline (representing a model or a combination of models) in its own serialization format that can be only used within Apache Spark. It is based on a combination of JSON describing metadata of the model/pipeline and Parquet for storing model data (weights etc.) itself. It is limited to the models available in Apache Spark and cannot be extended to additional models easily (expect by extending Apache Spark). As such it ranges between high to medium ambiguity. Flexibility is limited between low and medium flexibility, because it requires Apache Spark to run and there is limited to the models offered by Apache Spark. Clearly, one benefit is that it can store compositions of models.
Theano – Python serialization (Pickle)
Theano offers Python serialization (“Pickle”). This means nearly all (with some restrictions) that can be expressed in Python and its runtime data structures can be stored/loaded. Python serialization – as any other programming language serialization, such as Java – is very storage/memory hungry and slow. Additionally, the Keras documentation (see above) does not recommend it. It has also serious security issues when bringing models from development to production (e.g. someone can put anything there even things that are not related to machine learning and can exploit security holes with confidential data in production). Furthermore, serialization between different Python versions might be incompatible.
The ambiguity is low to medium, because basically only programming language concepts can be described. Metadata, ontologies etc. cannot be expressed easily and a lot of unnecessary Python-specific information is stored. However, given that it offers the full flexiblity of Python it ranges from medium to high flexibility.
Some data science tools allow to define a model in a so-called software container (e.g. implemented in Docker). These are packages that can be easily deployed and orchestrated. They basically allow to contain any tool one wants. This clearly provides a huge flexibility to a data scientists, but at the cost that usually the software containers are not production ready as they are provided by data scientists, who don’t have the same skill as enterprise software developers. Usually they lack an authorization and access model or any hardening, which makes them less useful for confidential or personal data. Furthermore, if data scientists can install any tool then this leads to a large zoo of different tools and libraries, which are impossible to maintain, upgrade or apply security fixes. Usually only the data scientist that created them knows the details on how the container and the containing tools are configured making it difficult for others to reuse it or to scale it to meet new requirements. Containers may contain data, but this is usually not recommended for data that changes (e.g. models etc.). In these cases one needs to link a permanent storage to the container. Of course, the model format itself is not predefined – any model format maybe used depending on the tools in the container.
As such they don’t provide any mean to express any information of the model, which means they have a very high ambiguity. However, they have a high flexibility.
Jupyter notebooks are basically editable webpages in which the data scientist can write text that describes code (e.g. in Python) that is executable. Once executed the page will be rendered with the results from the executed code. These can be tables, but also graphs. As such, notebooks can support various programming languages or even mix different programming languages. Execution depends on data stored outside the notebook on a storage in any format that is supported by the underlying programming language.
Descriptions can be as rich, but they are described natural language and thus difficult to process by an application, e.g. to reuse it in another context, or to integrate them into a complex machine learning pipeline. Even for other data scientists this can be difficult if the descriptions are not adequate.
Notebooks can be more understood in the scientific context, ie writing papers and publishing them for review, which does not address all the use cases described above.
As such it provides high flexibility and medium to high ambiguity.
Conclusion
I described in this blog post the importance of the storage format for machine learning models:
- Bring machine learning models from the data scientist to a production environment in a secure and scalable manner where they are reused by applications and other data scientists
- Sharing and using machine learning models cross systems and organizational boundaries
- Offering pretrained machine learning models to a wide range of customers
- (Automatically) composing different models to create a new more powerful combined model
We have seen many different solutions across the dimensions flexibility and ambiguity. There is not one solution that fits it all for all use cases. This means there is no perfect standard solution. Indeed, an organization will likely employ two or more approaches or even potentially combine them. I see in the future four major directions:
- Highly standardized formats, such as the portable format for analytics (PFA), that can be used across applications and thus data scientists using them
- Flexible descriptive formats, such as notebooks, that are used among data scientists
- A combination of flexible descriptive formats and highly standardized formats, such as using PFA in an application that is visualized in a Notebook at different stages of the machine learning pipeline
- An extension of existing formats towards online machine learning, ie updatetable machine learning models in streaming applications
Schreibe einen Kommentar