Ilustration of the memory allocation process for exchanging data between application and module
2022-08-01 --- Jörn Franke
I have also published the source code of this on Codeberg (EU Git hosting) and Github (US Git hosting).
Nowadays we have a plethora of programming languages and platforms at our fingertips. They have different advantages and disadvantages depending on the use case and preferences. Often many different combinations of components are used for data processing. I will investigate in this post how to create a system that can dynamically load different modules written in different programming languages for different platforms to enable different types of data processing.
Within this study I prototyped a very simple application in Rust that can load different modules dynamically. Those modules are compiled to WebAssembly (a cross-programming languages and cross-platform executable) beforehand. Apache Arrow is used as a serialization format for (big) data exchange between modules that works cross-platform/cross-programming language. I will discuss some advantages and limitations of this approach. Finally, I will also explain if the limitations can be overcome in the future and how.
This is a hypothetical case: We want to build a flexible data pipeline processing engine with the following requirements:
I will explain only some implementation aspects of which for some of those that I describe more details can be found in the source code (see top of this post).
The requirements are mostly addressed by compiling the modules to WebAssembly (WASM) and by using the WASM System Interface (WASI) - you can find more details on both technologies in a previous post.
The exchange of data between the application and modules is of key importance. I want to highlight in this section the basic process as well as issues.
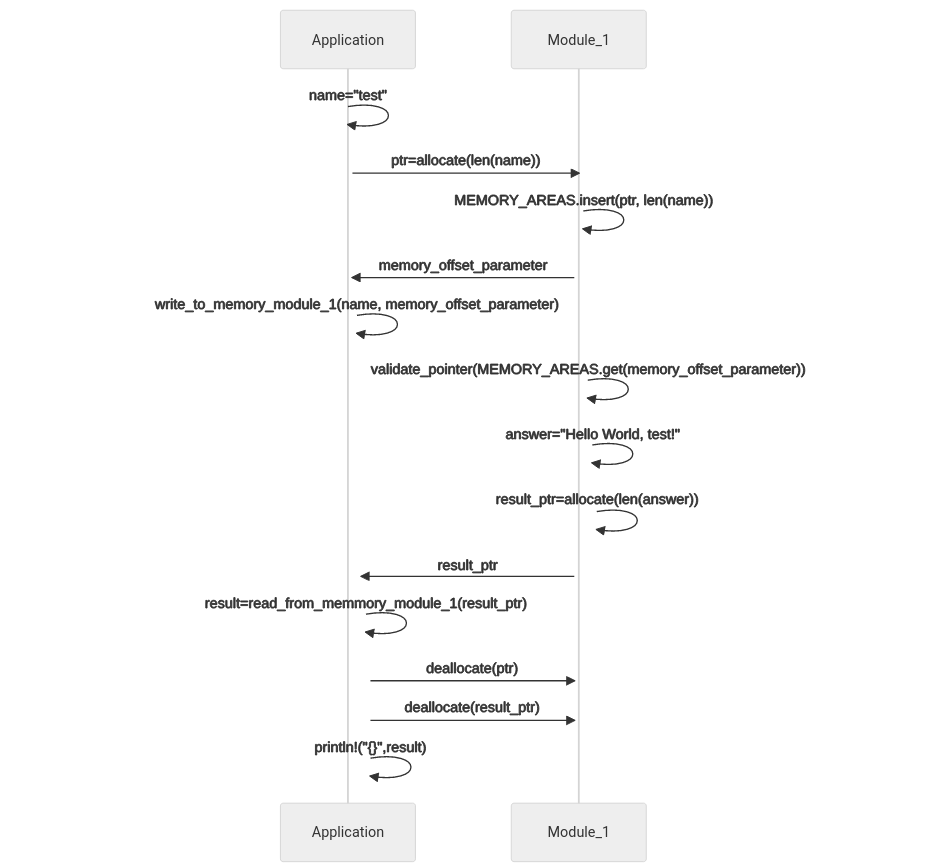
As mentioned before, the memory of the module is at the same time shared so the application and the module can exchange data. This can be problematic for the module (the application is not/very little affected by this), because a bug in the application may override parts of the module memory leading to data corruption or a malfunctioning module.
To avoid this, the memory of all data that is exchanged between application to module as well as module to application needs to be managed by the module. For instance, if the application wants to provide a parameter that requires memory, such as in the study a name that is represented by a string - it needs to first ask the module to allocate some memory and provide a pointer to which the application can write the string.
Additionally, once the module needs to return data, e.g. a string that says “Hello World, name”, where name comes from the parameter that was provided by the application in the module memory, it needs also to allocate some memory for this. The reason is that it needs to keep the data available in memory for the application - no automated removal or garbage collection should take place - before the application has read it. This is especially crucial when combining different types of programming languages.
Once the function of the module returns, the application needs to tell the module that it read the return data and that it can deallocate the memory reserved for the parameter and for the return data. I illustrate this in the following figure:
Ilustration of the memory allocation process for exchanging data between application and module
This is already one thing that one needs to consider if you want to allow dynamically loaded modules written in different programming languages.
There are further things to consider.
The application needs to decide on how much memory it grants to the module via the WASM runtime. This is based in pages of a certain size (usually 64 KB). When you need to exchange larger data volumes with a module, then you need to provide the corresponding amount of pages in memory or the module will run out of memory.
The application and/or module may have an exception or a bug so memory that could be released was not released. Over time more and more memory might not be released and thus the module runs out of memory. Here, the application could periodically check when the memory was last accessed and deallocate if it was longer time ago.
Writing to only one memory which also contains the module code can be problematic as explained before. It would be better if the module has its own memory, the application has an additional memory to write the parameters to and the module as an additional memory to write the return data to. While you still need an allocation mechanism (which you then can put also in the application to make it even more safe and reusable across different programming languages/platforms), it would decrease the risks of side-effects significantly. This will be possible with the new WASM multi-memory proposal which is in progress of being implemented.
I have not talked about threads yet (neither in application or module side), but for the current WASM implementation, I recommend that each threat creates its own instance of the module and module instances are not shared.
I have presented before how to exchange data between the application and the dynamically loaded module. However, I did not say how the data should be structured. This is a very important question given the requirement that we need to exchange data between modules written in many different programming languages.
The WASM standard currently does not prescribe how data should look like. For example, a string in C must end with \0 - this is different from a string in Rust or Python. Similarly all non-primitive types, e.g. Arrays, Structs, Maps etc., are represented differently in all programming languages. There is an upcoming standard - the WASM component model, which will include the previous proposal for WASM Interface Types (WIT) that standardize it.
While one could now convert/or standardize the data to be exchanged using an own standard or a future standard, there are still issues for our use case. Even the standard, e.g. WIT, would need to be frequently translated to/from the native implementation of each programming language, which costs a lot of time. It has been mainly designed for calling functions with parameters and get simple result back. This is fine for many use cases that just require this.
However, it has not been designed for massive data exchange between application and modules written in different programming languages. They would not perform if the data constantly needs to be translated into different representations. Furthermore, often the whole data needs to be available, but then given the data a module needs to be able to rapidly select only a small part according to different criteria and work only on this small part of the data. This would be extremely inefficient using the standard parameter/result model.
A good solution to this seems to be Apache Arrow - A cross-language development platform for in-memory analytics. Apache Arrow allows to represent data in memory in a very compact efficient format that can be rapidly be queried and worked on in different programming languages reducing the need for costly serialization/deserialization. I used Apache Arrow in the second module compiled to WASM. The application provides some input data in Arrow format (IPC serialization) to the module and the module could read the data as well as provide an answer in Arrow format (IPC serialization) back.
This seems to be also rather fast. Only the first time when the module is instantiated (which you only need to do once during the application lifetime), it takes a bit longer to load the module containing the Arrow library. After this it works very fast. I believe the loading of the Arrow library in the module can significantly be reduced in the future as well.
I believe I have for my use case a working stack based on dynamically loadable modules in WASM. However, since the WASM standard is constantly evolving, there are future extensions that are relevant for this use case:
I presented here a study for dynamically loading modules written in different programming languages for a use case of a highly modular data processing engine that can be deployed on embedded devices up to large scale clusters in the cloud. This is demonstrated by the freely available code of the study. The modules are compiled to WASM which makes them universally usable on all platforms without providing platform-specific binaries. Although WASM is still under a lot of development, it is used in different production application already nowadays.
The study showed that the use case can be implemented already now and it can even benefit more in the future as current WASM proposals are implemented as extensions.
It also showed that exchange of data - as envisioned in the use case - should be implemented with great care. Apache Arrow seems to be a suitable in-memory data format for this. Exchanging data across modules in different programming languages also implies that the memory management for this data cannot rely only on mechanisms implemented in individual languages, such as garbage collection. Nevertheless, the safety features of WASM memory prevents already today some risks associated with this and will include in the future even more. However, the mechanisms in the application still need to be designed, implemented and tested with great care.
I think the vision of limitless modularity becomes more and more implemented and I am also convinced that I have a way forward for my use case that can be implemented now.