This blog post is discussing the implications of Unikernels, Software Containers and Serverless Architecture on Modularity of complex software systems in a service mesh as illustrated below. Modular software systems claim to be more maintainable, secure and future proven compared to software monoliths.
Software containers or the alternative MicroVMs have been proven as very successful for realizing extremely scalable cloud services. Examples can be found in the areas of serverless computing and Big Data / NoSQL solutions in form of serveless databases (which are often not realized using containers). This has gone so far that upon a web request of a user the software container is started that executes a business function developed by a software engineer, an answer to the user is provided and then software container is stopped. Thus, large cost savings can be realized in a cloud world where infrastructure and services are payed by actual consumption.
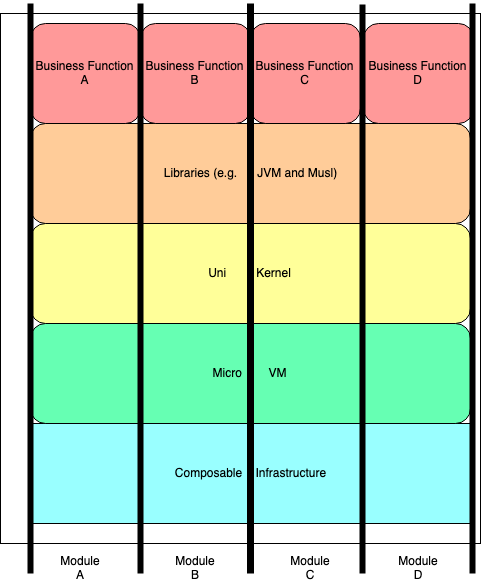
However, we will see in this post that there is still room for optimization (cost/performance) to modularize the application, which is usually based still on large monolith, such as the Java Virtual Machine with all standard libraries or the Python environment with many libraries that are in most cases not used at all to execute a single business function. Furthermore, the operating system layer of the container is also not optimized towards the execution of a single business function as they contain much more operating system functionality than needed (e.g. drivers, file systems, network protocols, system tools etc.). Thus Unikernels are an attractive alternative to introduce cost savings in the cloud infrastructure.
Finally, we will discuss grouping of functions, ie where it make sense to combine a set of function of your application composed of single functions/microservices to one unit. Briefly we will address composable infrastructure.
Background: Software Containers and Orchestrators
The example above of course is a simplistic example and much more happens behind the scene. For example, the business function may need to fetch data from a datastore. It may need to communicate with other business functions to return an answer. This requires that these business functions, communication infrastructure and datastores need to work together, ie they need to be orchestrated. Potentially additional hardware (e.g. GPUs) need to be taken into account that is not all the time available due to cost.
This may imply, for example, that these elements run together in the same virtual network or should run on the same servers or servers close to each other for optimal response times. Furthermore, in case of failures they need to be rerouted to working instances of the business function, the communication infrastructure or the data store.
Here orchestrators for containers come into play, for example Kubernetes (K8S) or Apache Mesos. In reality, much more need to be provided, e.g. distributed configuration services, such as Etcd or Apache Zookeeper, so that every component always finds its configuration without relying on complicated deployment of local configuration files.
Docker has been a popular concept for software containers, but it was neither the first one nor was it based on new technologies. In fact, the underlying module (cgroups) of the Linux kernel has been introduced years before Docker emerged.
This concept has been extended by so-called MicroVM technologies, such as Firecracker, based on UniKernels to provide only the OS functionality needed. This increases reliability, security and efficiency significantly. Those VMs can startup much faster, e.g. within milliseconds, compared to Docker containers and thus are more suitable even for simple use cases of web service requests described above.
About UniKernels
UniKernels (also known as library operating systems) are core concept of modern container technologies, such as Firecracker, and popular for providing cloud services. They contain only the minimum set of operating system functionality necessary to run a business function. This makes them more secure, reliable and efficient with significant better reaction times. Nevertheless, they are still flexible to be able to run a wide range functionality. They contain thus a minimal needed kernel and a minimal needed set of drivers. UniKernels have been proposed for various domains and despite some successes to run them productively they are at the moment still a niche. Examples are:
- ClickOs: Dynamically create new network devices/functions (switching, routing etc.) within milliseconds on a device potentially based on a software-defined network infrastructure
- Runtime.js: A minimal kernel for running Javascript functions
- L4 family of microkernels
- Unik – compile application for using in UniKernels in Cloud environments
- Drawbridge – a Windows-based UniKernel
- IncludeOS – A lightweight Linux OS for containers/MicroVMs
- Container Linux (formerly: CoreOS): A lightweight OS to run containers, such as Docker, but more recently based on rkt. While this approach is very light-weight, it still requires that the rkt containers that are designed by developers are light-weight, too. Especially care must be taken that different containers do not only include the libraries necessary, but also only the parts of the libraries necessary and only one version of them.
- OSv – run unmodified Linux application on a UniKernel
- MirageOS – Ocaml based
Serveless Computing
Serverless computing is based on MicroVMs and Unikernels. Compared to the traditional containerization approaches this reduces significantly the resource usage and maintenance cost. On top, they provide a minimum set of libraries and engines (e.g. Java, Python etc.) to run a business function with ideally the minimum needed set of functionality (software/hardware). Examples for for implementations of serverless computing are OpenFass , Kubeless or OpenWhisk. Furthermore, all popular cloud services offer serverless computing, such as AWS Lambda, Azure Functions or Google Cloud Functions.
The advantage of serverless computing is that one ideally does not have to design and manage a complex stack of operating systems, libraries etc., but simply specifies a business function to be executed. This reduces significantly the operating costs for the business function as server maintenance, operating system maintenance, library maintenance are taken over by the serverless computing platform. Furthermore, the developer may specify required underlying platform versions and libraries. While those are usually offered by the service provider out of the box, they need to be created manually by them or the developer of the business function.
Those libraries that provide the foundation for a business function should ideally be modularizable. For example, for a given business function one does not need all the functionality of a Java Virtual Machine (JVM) including standard libraries. However, only recently Java has introduced a possibility to modularize the JVM using the Jigsaw extension that came with JDK9. This is already an improvement for more efficiency when using serverless computing, but the resulting modules are still comparably coarse grained. For example, it is at the moment not possible to provide to the Java compiler a given business function in Java and it strips out of the existing standard libraries and third party libraries only the functionality needed. This still highly depends on the developer and also there are some limits. For other libraries/engines, such as Python, the situation is worse.
The popular standard library (glibc) is also a big monolith library that is used by Java, Python, native applications and kernels that has a lot of functionality that is not used by a single business function or even application. Here alternatives exists, such as Musl.
This means that currently perfect modularization cannot be achieved in serverless computing due to the lack of support by underlying libraries, but it is improving continuously.
Service Mesh
A service mesh is a popular mean for communication to and between functions in serverless computing. Examples for service mesh technologies are Istio, Linkerd or Consul Connect. Mostly this refers to direct synchronous communication, because asynchronous communication, which is an important pattern for calling remote functions that take a long time to complete, such as certain machine learning training and prediction tasks, is not supported directly.
However, you can deploy any messaging solution, such as ZeroMQ or RabbitMQ, to realize asynchronous communication.
The main point here is that service meshes and messaging solutions can benefit a lot from modularization. In fact, the aforementioned Clickos is used in network devices to spawn up rapidly any network function as a container that you may need from the network device, such as routing, firewall or proxying. Those concepts can be transferred to services meshes and messaging solution to deliver only the minimal functionality needed for a secure communication between serverless computing function.
The modularization of the user interface
One issue with user interfaces is that they basically provide a sensible composition of business functions that can be triggered by them. This means they support a more or less complex business process that is executed by one or more humans. In order to be usable they should present a common view on the offered functionality to the human users. New technologies, such as Angular Ivy, supports extracting from a UI library only the needed functionality reducing code size, security and reliability of the UI.
The aforementioned definition of UI means that there is at least one monolith that combines all the user interfaces related to the business functions in a single view for a given group of users. Since decades there are technologies out there that can do this, such as:
- Portals: Portlets. More structured UI aggregation already at server side
- Mashups: Loosely coupling of UIs using various „Web 2.0“ technologies, such as REST, Websockets, JSON, Javascript, and integrating content from many different services
One disadvantage with those technologies is that a developer needs to combine different business functions into a single UI. However, the user may not need all the functionality of the UI and it cannot be expected that a developer manually combines all UIs of business functions for different user groups.
It would be more interesting that UIs are combined dynamically given the user context (e.g. desk clerk vs stewardess) using artificial intelligent technologies. However those approaches exist in academia since many years, but have not yet been managed to use in a production environment at large scale.
Finally, one need to think about distributed security technologies, such as OpenID:Connect, to provide proper authentication and authorization to access those UI combinations.
Bringing it all together: Cloud Business Functions and Orchestration
With the emergence of serverless computing, Microservices and container-based technologies we have seen the trends towards more modularization of software. The key benefits are higher flexibility, higher security and simpler maintenance.
One issue related to this is how to include only the minimal set of software to run a given business function. We have seen that it is not so easy and currently one still has to include large monolith libraries, such as Glibc, Python or Java, to run a single business function. This increases the risk of security issues and requires still big upgrades (e.g. moving to another major version of an underlying library). Additionally, also the underlying operating system layer is far form being highly modularizable. Some operating systems exist, but they remain mostly in the domain of highly specialized devices.
Another open question is how to deal with the feature interaction problem as the possible number of combinations and modules may have unforeseen side-effects. On the other hand, one may argue that higher modularization and isolation will make this less of a problem. However, those aspects still have to be studied.
Finally, let us assume several business functions need to interact with each other (Combined Business Functions – CBF). One could argue that they could share the same set of modules and versions that they need. This would reduce complexity, but this is not always easy in serverless computing, where it is quite common that a set of functions is developed by different organisations. Hence, they may have different versions of a a shared module. This might be not so problematic if even in different versions the underlying function has not changed. However, if it changes then it can lead to subtle errors if two business functions in serverless computing need to communicate. Here it would be desirable to capture those changes semantically, e.g. using some logic language, to automatically find issues or potentially resolve them in the service mesh / messaging bus layer. One may think in this context as well that if business functions run on the same node they could share potentially modules to reduce the memory footprint and potentially CPU resources.
Answers to those issues will also make it easier to upgrade serverless computing functions to the newest version offering the latest fixes.
In the future, I expect:
- CBF Analyzer that automatically derive and extract the minimum set of VM, uni kernel, driver and library/engine functionality needed to run a business function or a collection of loosely coupled business functions
- Extended Analysis on colocating CBFs that have the optimal minimum set of joint underlying dependencies (e.g. kernel, driver etc.)
- Dynamically during runtime of a function making shared underlying modules in native libraries and operating system code available to reduce resource utilization
- Composable infrastructure and software-defined infrastructure will not only modularize the underlying software infrastructure, but the hardware itself. For instance, if only a special function of a CPU is needed then other part of the CPUs can be used by other functions (e.g. similar to Hyper-Threading). Another example is the availability and sharing of GPUs by plugging them anywhere into the data center.
Schreibe einen Kommentar